Growth Hacking Course
GTM Infrastructure MVP: Build the Smallest Thing That Can Kill Your Assumptions
By
June 22, 2026

Product teams stopped shipping fully-formed features a decade ago. The feedback loop kept proving them wrong. GTM teams still design and build complete systems before testing a single assumption embedded in them.
That's why so many expensive builds get quietly shelved.
The fix isn't a better build sequence. It's a fundamentally smaller first build - a GTM infrastructure MVP designed to invalidate your riskiest assumptions before you commit capital to the full system. Most SaaS companies don't have a lead problem. They have an assumption problem they've accidentally encoded into infrastructure.
The quiet shelving problem

Nobody in GTM talks about this openly.
A company spends 4 to 6 months speccing, procuring, and wiring together a go-to-market infrastructure - CRM architecture, enrichment layer, outbound sequences, routing logic, attribution model, the lot. It launches late. It costs more than projected. And within 90 days of going live, the team is already working around it, rebuilding pieces of it, or quietly deprioritising it in favour of manual workarounds.
The build gets shelved. Not announced as a failure - just gradually abandoned. The tooling invoices keep coming. The data stays dirty. The next planning cycle opens with "we need to fix our GTM infrastructure" and the cycle repeats.
This isn't a tooling problem. It's an epistemological one.
The team was overconfident in assumptions about ICP fit, motion, channel response, and message resonance before they had any feedback - and then they built infrastructure that locked those assumptions in at scale.
Charara, co-founder of RevenueHero, put it plainly: "What really gets underestimated in building go to market AI systems is the effort that goes prior to actually launching something that's useful, which is mostly a lot of ops work, a lot of cleanups, a lot of standardization and just a lot of the unsexy work that doesn't get spoken about."
The unsexy work isn't just operationally hard. It's assumption-dense. Every data cleaning decision, every field mapping, every routing rule encodes a belief about how your buyers behave. If those beliefs are wrong, you've built a very expensive wrong answer.
What product figured out that GTM hasn't

In product development, assumption mapping is standard practice.
Before a team commits to building a feature, they enumerate the beliefs the feature depends on - that users have this problem, that they'll discover the feature this way, that the workflow fits how they actually work - and rank those assumptions by 2 variables: how confident are we, and how expensive is it to discover we were wrong?
Low-confidence, high-cost-to-discover-late assumptions get tested first, cheaply, before any code ships at scale.
GTM infrastructure builds contain exactly the same structure of embedded assumptions. The difference is that GTM teams almost never map them. They treat the build as a technical and operational challenge - what components, in what order, connected how - rather than as an epistemological one. Every top-ranking article on GTM infrastructure assumes the destination is a complete, integrated system and debates only the assembly sequence. The MVP-first mental model doesn't exist in that conversation.
It should.
Mapping assumptions before you build
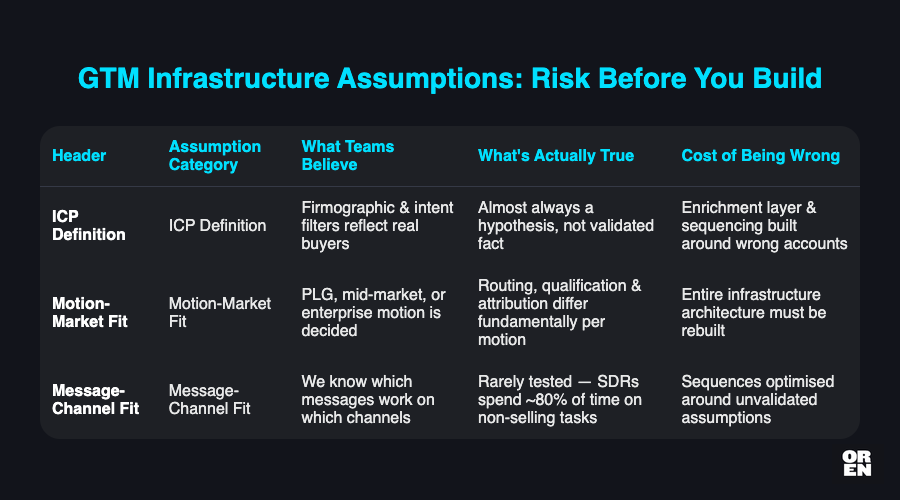
A GTM infrastructure MVP starts with a specific question: which of the beliefs embedded in this system design are most likely to be wrong, and most expensive to discover after we've built around them?
GTM teams are consistently overconfident in a few categories.
ICP definition. Most teams believe they know their ICP more precisely than they do. Firmographic filters, technographic signals, intent data triggers - these all encode assumptions about which accounts are actually worth pursuing. Amplify Group observed this pattern across 30+ B2B companies: the ICP definition driving the enrichment layer and sequencing logic is almost always a hypothesis, not a validated fact [Amplify Group, 2026].
Motion-market fit. Whether you're running product-led, mid-market direct, or enterprise isn't just a positioning decision - it determines the entire architecture of your GTM system. Routing logic, qualification criteria, sequence cadence, and attribution model all differ fundamentally between motions. I've written before about why committing to a single GTM motion before expanding is non-negotiable - but the infrastructure build forces that commitment whether you're ready or not. If you're not certain of your motion, don't build motion-specific infrastructure at scale.
Message-channel fit. Which messages resonate with which buyer personas on which channels is almost always assumed, rarely tested. SDRs spend up to 80% of their day on non-selling activities [EdgeMindLab, 2026] - which means the message and channel assumptions embedded in outbound sequences are rarely stress-tested before they get automated at volume.
Data quality as a foundation. This one gets underestimated almost universally. Charara again: "The foundation for AI, as it has always been for ML in its previous form, is garbage in garbage out."
If your CRM data is dirty - and it almost certainly is - every automation layer you build on top of it amplifies the noise. Sales forecasting accuracy only reaches within ±10% with clean CRM hygiene [DevCommX, 2026]. Most teams discover their data quality problem after they've built the system that depends on it.
What a GTM infrastructure MVP actually looks like
A GTM infrastructure MVP isn't a scaled-down version of the full system. It's a deliberately incomplete, deliberately cheap version designed to generate signal on your riskiest assumptions before you commit to the full build.
One motion, one segment, one channel. Not all 3 simultaneously. Pick the motion you're most confident in, the ICP segment with the most evidence behind it, and the channel where you have the most existing signal. Build only what's needed to run that combination cleanly. Everything else waits.
Manual before automated. Before you build enrichment automation, enrich 50 accounts manually and check the output quality. Before you automate outbound sequences, write and send 30 manually and measure response rates by message variant. The manual version is your assumption test. The automated version is only justified once the manual version produces signal worth scaling.
Instrument before you optimise. The most common failure in early GTM infrastructure builds is optimising processes that aren't yet measured. EdgeMind Lab put it simply: "Without measurement, optimisation becomes impossible." Teams build routing logic, enrichment flows, and sequence automation before they have baseline conversion data at each stage. The MVP inverts this: instrument first, automate second.
Timebox ruthlessly. A GTM infrastructure MVP should produce signal within 30 days, not 90. If you can't get meaningful feedback in 30 days, the scope is too large or the assumptions aren't actually testable - both of which are important discoveries.
This is directly analogous to what a growth audit surfaces: companies that execute in the wrong order - buying tools and hiring people before defining strategy - consistently underperform those that validate assumptions first and build around confirmed signal.
The scale argument is a trap
The most common objection to the MVP approach is the scale argument: "We need the full system because manual processes don't scale."
Technically true. Strategically irrelevant at the point most teams make this argument.
AI infrastructure can research and execute personalised outreach to 30,000 accounts where a human might research 30 a day [EdgeMindLab, 2026]. That 1,000x multiplier is real. But if the ICP definition, message, or channel assumption embedded in that outreach is wrong, you've scaled the wrong thing by 1,000x. You haven't built a pipeline. You've built a reputation problem.
Scale is the reward for validated assumptions, not the precondition for testing them.
The teams that reach 3x outbound pipeline volume within 90 days of system launch [DevCommX, 2026] aren't the ones who built the most comprehensive system first. They're the ones who built the right system - which requires knowing what 'right' means before you build it.
The GTM Engineer's job - distinct from RevOps, which owns in-pipeline operations - is to own the pre-pipeline building work. That work starts with assumption validation, not infrastructure assembly. Treating the build as the primary deliverable confuses output with outcome.
The build order that actually works
Weeks 1-2: Assumption audit. List every belief your proposed system design depends on. Rank by confidence and cost-to-discover-late. Identify the 3-5 assumptions that are both low-confidence and high-cost. These are your MVP's targets.
Weeks 3-4: Manual validation sprint. Run the highest-risk assumptions manually. Enrich accounts by hand. Send sequences personally. Route leads through a spreadsheet. The goal isn't efficiency - it's signal.
Weeks 5-6: Instrument and measure. Build only the measurement layer first. Conversion rates by stage, response rates by message, qualification rates by ICP segment. This is your baseline.
Weeks 7-8: Automate one thing. Pick the single highest-confidence, highest-volume process and automate it. Not everything - one thing. Measure the delta between manual and automated output quality.
Week 9+: Expand from evidence. Each subsequent automation decision is justified by data from the previous stage, not by the original system design.
This isn't slower than the traditional approach. The traditional approach produces a 6-month build that gets quietly shelved. The MVP approach produces a system that compounds because each layer is built on validated ground.
The assumption you can't afford to get wrong last
If you've watched a GTM infrastructure project launch late, over budget, and immediately need reworking, the root cause is almost never the tools or the team.
It's that the system was designed around assumptions that were never tested - and the build process gave those assumptions the appearance of certainty.
EdgeMind Lab's framing is right: "Most SaaS companies don't have a lead problem. They have an execution problem." The execution problem, more precisely, is an assumption problem.
Build the smallest thing that can kill your riskiest assumption. Then build the next thing. The full system is the destination, not the starting point.





