Growth Hacking Course
Custom AI Pipeline Generation: The Wrong Question
By
June 25, 2026

28% of B2B sales reps hit quota last year. Down from 44% the year before [salesmotion.io, 2025]. Reps spend roughly 28% of their week actually selling [Clari, 2025]. Cold email reply rates sit between 1-5%, and 94% of buying groups have already ranked their shortlist before they ever speak to a vendor [salesmotion.io, 2025; Prospeo, 2026].
The pipeline problem is real. The vendor response to it is also real. And most CMOs and CROs evaluating tools right now are asking the wrong question entirely.
Build vs. buy is a cost question. The question that actually matters is a moat question: does your competitive edge in pipeline generation depend on proprietary data combinations that no vendor can replicate?
If it does, buying isn't saving you money. It's permanently capping your ceiling.
The median customer problem

There's a reason you've evaluated 3 or 4 AI pipeline tools and none of them quite fit. It's not the pricing tiers. It's not the integrations list.
It's that the tools are built for the median customer, and your competitive advantage - if you have one - is definitionally not median.
The market has split into 2 camps. AI-powered outbound platforms (Salesforge, Leadspicker, Apollo) that promise to automate prospecting at scale. And technical data pipeline frameworks for ML teams. Both camps treat the strategic question as already answered: buy the tool, configure it, run the plays.
What's missing from that framing is the moat question: does your pipeline advantage come from data combinations that a vendor serving 2,000 other customers structurally cannot access or replicate?
If yes, buying isn't a shortcut. It's a permanent constraint.
What vendors are actually selling

The pitch is automation: let AI handle the mechanical 80% so reps can focus on the 20% that closes. At the commodity layer, that's a reasonable pitch. If your ICP is findable in ZoomInfo, your signals are standard (job changes, funding rounds, technographics), and your differentiation lives in your product and your people rather than in how you identify and approach accounts - buy the tool. Configure it well. Move on.
But the vendor pitch doesn't address what happens when your edge is precisely in the data layer.
Consider what a custom AI pipeline system can fuse that no vendor touches: your CRM's 7 years of closed-lost notes and the language patterns in them, your product's behavioural telemetry showing which free-tier users exhibit pre-conversion signals, your customer success team's knowledge of which company characteristics predict expansion versus churn, your proprietary market intelligence from a vertical no data provider has adequately mapped.
None of that is in ZoomInfo. None of it is in Apollo.
A vendor can enrich a contact record. They cannot operationalise your institutional knowledge.
"This high prioritization underscores the strategic importance that leaders are placing in AI technologies for future growth and also to have a competitive advantage." - Abhilash Mula, Senior Manager, Product Management, Informatica
The companies that understand this aren't running the same AI plays as their competitors. They're building pipelines that improve asymmetrically - because the underlying data is proprietary, the system compounds in ways that a shared vendor platform cannot replicate for any single client.
The compounding returns argument
This is the part that gets underweighted in every build-vs-buy analysis I've seen.
Vendor tools optimise toward a benchmark. Organisations can reach roughly 50% of the value in time saved and response quality early in deployment, with up to 90% automation after multiple rounds of iteration and tuning [Matillion, 2025]. That's a real efficiency gain.
But efficiency against what baseline? Against the median GTM motion.
A custom pipeline trained on your proprietary data combinations doesn't just automate your existing motion - it creates a feedback loop that the vendor's roadmap will never prioritise for you specifically. Every iteration makes the system more calibrated to your buyers, your signals, your language. The gap between your system and a vendor tool widens over time rather than closing.
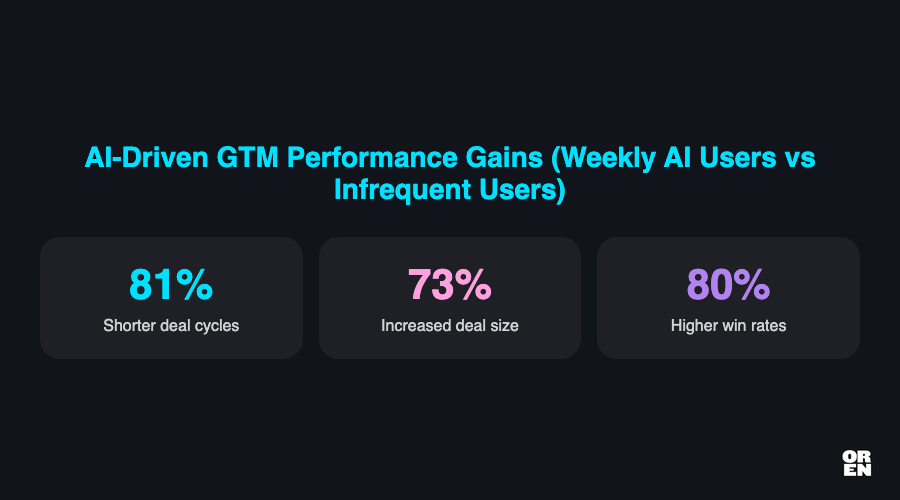
Teams using AI weekly already report 81% shorter deal cycles, 73% increased deal size, and 80% higher win rates compared to infrequent users [ZoomInfo, 2025]. Those numbers reflect frequency of use, not sophistication of the underlying system. The delta when the system itself is built on data your competitors cannot access is a different number entirely.
This is why I've argued elsewhere that your GTM stack is fundamentally an architecture problem, not a tooling problem. Buying another point solution - even a good one - doesn't resolve the architecture. It adds another layer to a Frankenstack that already can't talk to itself.
The proprietary data test
Before you make this decision, run this test. Ask your team to list every data source that is genuinely unique to your company - not data you can buy, but data you have because of the business you've built:
- Closed-lost CRM data with qualitative notes going back 3+ years
- Product usage telemetry tied to account-level firmographics
- Customer success interaction logs correlated with expansion or churn outcomes
- Niche vertical intelligence your team has accumulated that no data provider maps
- Behavioural patterns from your own community, events, or content ecosystem
- Signal combinations from your warmest audiences - existing customers, churned accounts, ex-customers now in new roles
That last category matters more than most GTM teams acknowledge. Starting with concentric circles - warmest to coldest - rather than defaulting to cold outreach is where the unit economics are most compelling. Only 27% of B2B leads are sales-ready when first generated, and 79% of marketing leads never convert to sales [Prospeo, 2026]. Your warmest audiences are the exception to both those numbers - and a vendor tool treats them the same as everyone else.
If your list of proprietary data sources is substantial, a vendor tool cannot operationalise it. Full stop.
If your list is thin - if you're essentially working with the same signals as your competitors - buying is rational. The question answers itself.
What building actually requires
This is where the argument gets uncomfortable.
Building a custom AI pipeline system is not a technical project with a marketing brief attached. It's a knowledge extraction problem that happens to have a technical implementation.
The hardest part isn't the architecture. It's getting your best GTM people to articulate the tacit knowledge they use to identify a good account, qualify a signal, or personalise an approach - the stuff that lives in their heads and has never been written down. That knowledge is the competitive asset. The AI system is just the vehicle for operationalising it at scale.
This is why leaders who delegate AI system builds entirely to technical teams get systems that are technically functional and strategically hollow. The strategic logic has to be in the room during the build, not bolted on at the end.
It also means the build-vs-buy question isn't purely about resources. It's about whether your leadership team has the AI fluency to own the strategic layer of a custom build. Most enterprise teams are stuck between stages 1 and 2 of AI maturity whilst claiming to the board they're adopting AI - counting licences activated rather than measuring capability built. If that's where you are, a vendor tool isn't just easier. It's the right sequencing. Build the capability first, then build the system.
The decision, stripped back
Three questions. That's all this is.
Is your pipeline edge data-dependent? If your best accounts are identifiable through signals that only exist inside your company, buying caps your ceiling at whatever the vendor's data model allows.
Do you have the internal capability to own a custom build strategically? Not technically - strategically. If the answer is no, sequence the capability build first.
What's the compounding trajectory? A vendor tool delivers efficiency now but plateaus at the vendor's roadmap. A custom system built on proprietary data improves asymmetrically. The question is whether your business operates on a timescale where that compounding matters.
Companies with documented pipeline generation strategies see 67% higher revenue growth - yet only 35% have a formal process in place [ziggy.agency, 2025]. The gap isn't tooling. It's strategic clarity about what the pipeline system is actually supposed to do and what data it needs to do it.
The real stakes
The vendors aren't wrong that AI transforms pipeline generation. Bain's data shows early adopters seeing 30%+ improvement in win rates when AI improves conversion across multiple funnel steps, and AI can effectively double the time sellers spend actually selling [Bain, 2025].
But 'using AI for pipeline' is not a strategy. It's a category.
The question is whether your implementation of AI pipeline generation is a source of durable advantage or a commodity capability your competitors can replicate by subscribing to the same tool next quarter.
If it's the latter, the vendor tools are fine. If it's the former, you're not facing a build-vs-buy decision. You're facing a question about whether you're willing to do the harder, slower, more strategically intensive work of building something that compounds - and whether you have the internal capability to do it well.
Most companies don't realise they've already hit the ceiling.





